
#code
Refactor your code with regex capture groups
Complex refactors are always a mix of manual and automated work. In this post, I'll show you how to use regex capture groups to make your refactors more efficient.
Consider the following real-world scenario:
Moving Javascript project to Typescript
You renamed all your .js, .jsx to .ts and .tsx, but now its time to add types to your React components. One of the pattern I've been using a lot in my Typescript projects is this:
interface Props {
// ...
}
const MyComponent: React.FC<Props> = ({ prop1, prop2 }) => {
// ...
};
However, in your newly created .tsx files, you have only:
const MyComponent = ({ prop1, prop2 }) => {
// ...
};
Of course, you could add interface declaration and type manually to each component, but that would be a lot of work, if you have, for example 100 components. Instead, you can use regex capture groups to make this a lot easier.
If you have only one exported const per .jsx file, then you could safely proceed with this approach.
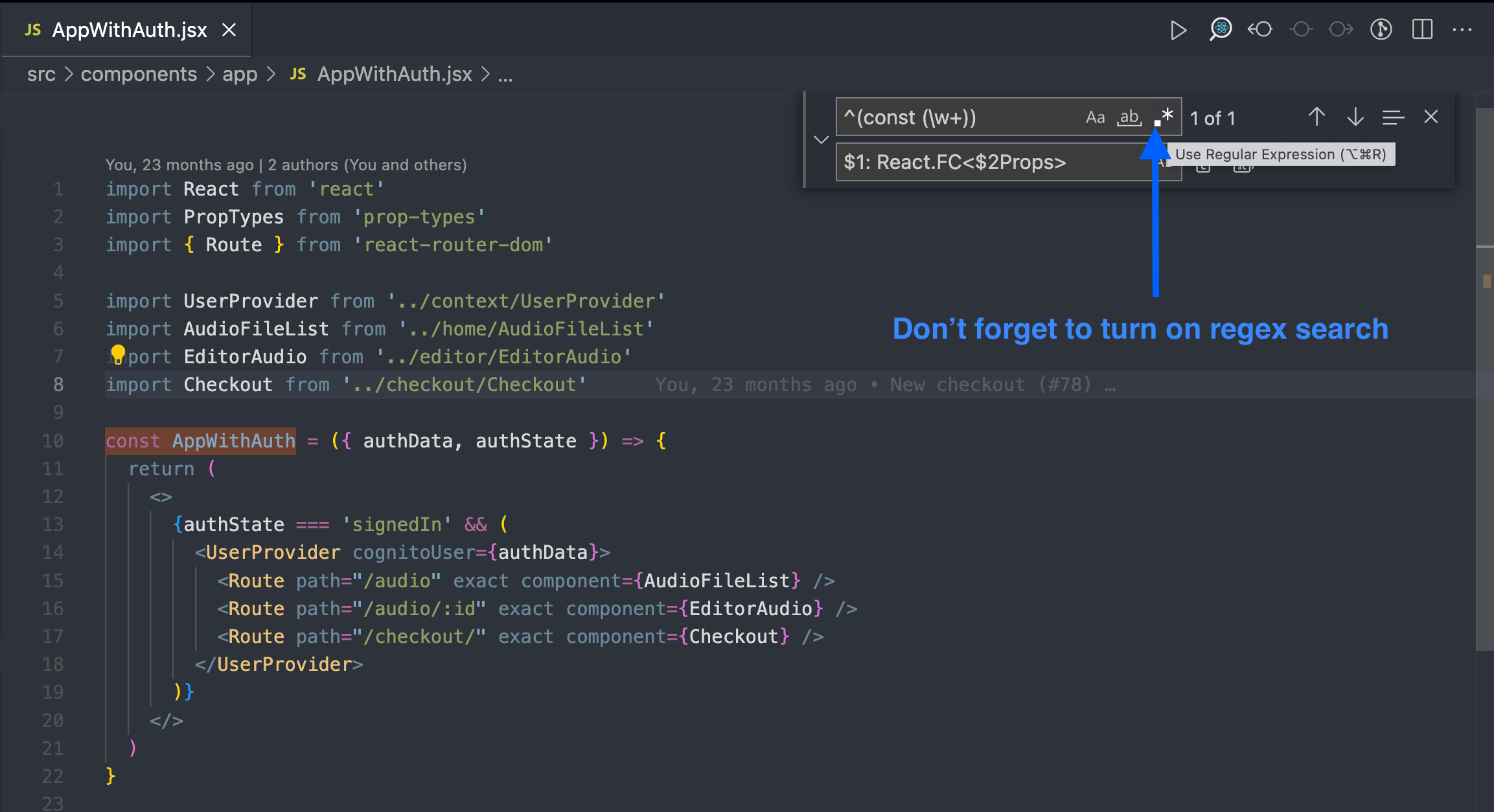
Find: ^(const (\w+))
Replace: $1: React.FC<$2Props>
Lets break this down:
^ - start of line
() - a capture group. Whatever is "captured" inside parenthesis could be referenced later with $1 or $2, depeding on the order of the capture groups
\w+ - \w - any word character, + - means one or more times
In the first capture group we have const AppWithAuth, in the second - AppWithAuth, so when we use $1, we get const AppWithAuth, and with $2, we get AppWithAuth.
Now, if we wanted our regex expression to work for the whole line, capturing props to be used within interface AppWithAuthProps,
we could use the following regex:
Find: ^(const (\w+))\s+=\s\((\{*.+\})\) => \{
Replace: interface $2Props\n$3\n\n$1: React.FC<$2Props> => {
This gives us:
interface AppWithAuthProps
{ authData, authState }
const AppWithAuth: React.FC<AppWithAuthProps> = ({ authData, authState }) => {
Again, it is the same principle, you are trying to match the whole line using capture groups, to catch the parts you need later.
Here you are also using \{*.+\} that might seems like a dark sorcery, but it is actually a very simple regex expression.
It means "any character that starts with opening curly brace, one or more times, followed by a closing curly brace":
\{ - matches { character, \ means escaped - we need to tell regex engine that we want to match { character, not the special meaning of { in regex.
* - zero or more times,
. - any single character except line terminators,
+ - any character one or more times
\s+ - matches any whitespace character one or more times
Obviusly, regex cannot help you provide the correct types, but it can help you with the boilerplate and mundane manual work. And if you have Prettier installed, then you are just one "save" away from having your code formatted properly.
